数据视图用于从数据源中选取所需的数据,并支持对所选数据进行转换和加工;加工逻辑和字段模型会被保存下来,用于分析和可视化制作
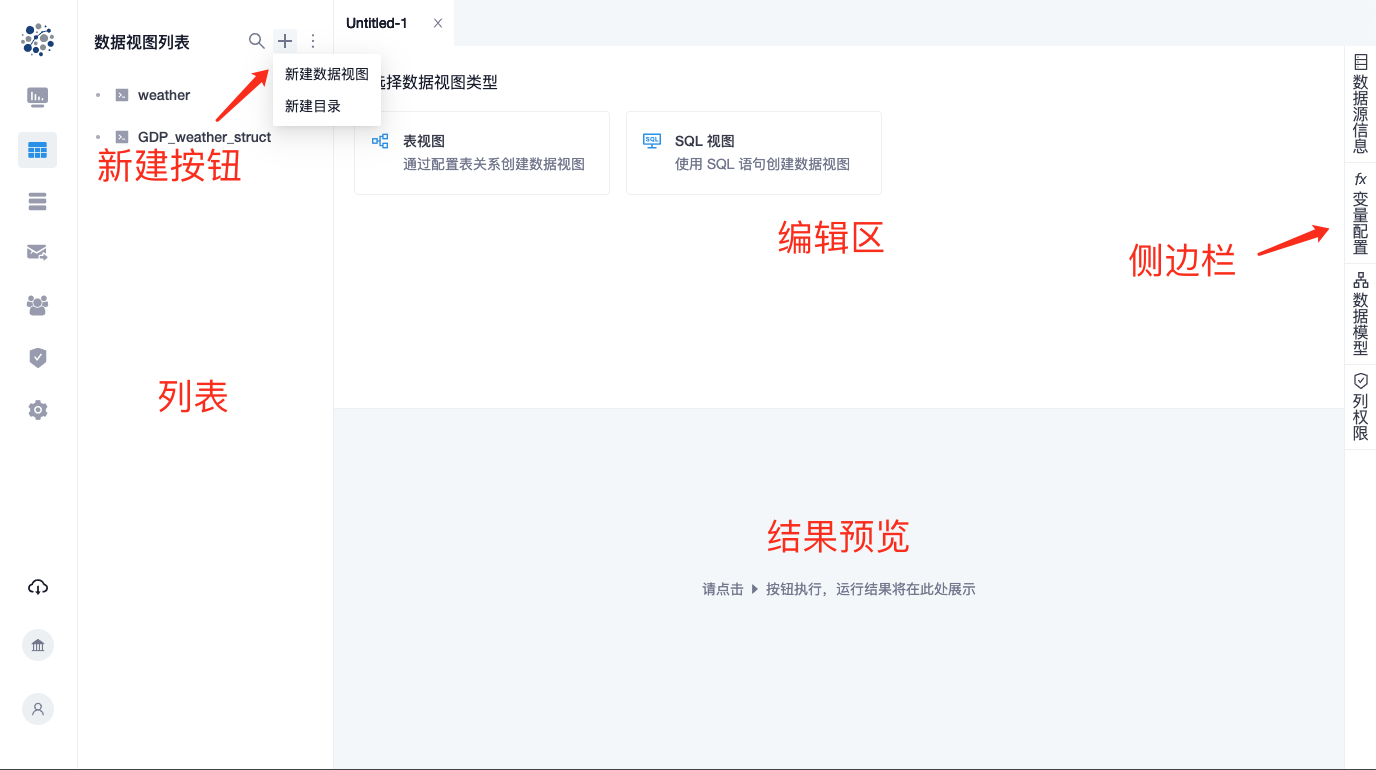
点击数据视图列表顶部的加号按钮,选择新建数据视图,右侧区域顶部会打开一个新标签页;标签页面板分为上、下和侧边栏 3 部分,上半部分是编辑区,下半部分是查询结果预览区,侧边栏用于浏览数据源信息、设置变量、数据模型和列权限
1. 类型
datart 支持两种类型的数据视图:
- 表视图:通过配置数据源表之间的关联关系来创建数据视图
- SQL 视图:通过 SQL 语句创建数据视图

2. 加工流程
一个数据视图的加工流程如下:
- 选择数据视图类型
- 配置表关系 / 编辑 SQL 语句
- 成功执行之后,预览查询结果,设置数据模型和列权限
- 保存数据视图;需要注意,只有整体成功执行之后才能保存(执行片段、或执行当前步骤都不行)
3. 表视图
表视图通过从数据源中选择数据表,然后配置它们之间的关联关系,来获取最终需要的数据。
选择表视图时,编辑区将引导式地展示配置步骤;首先需要从数据源中选择一张主表
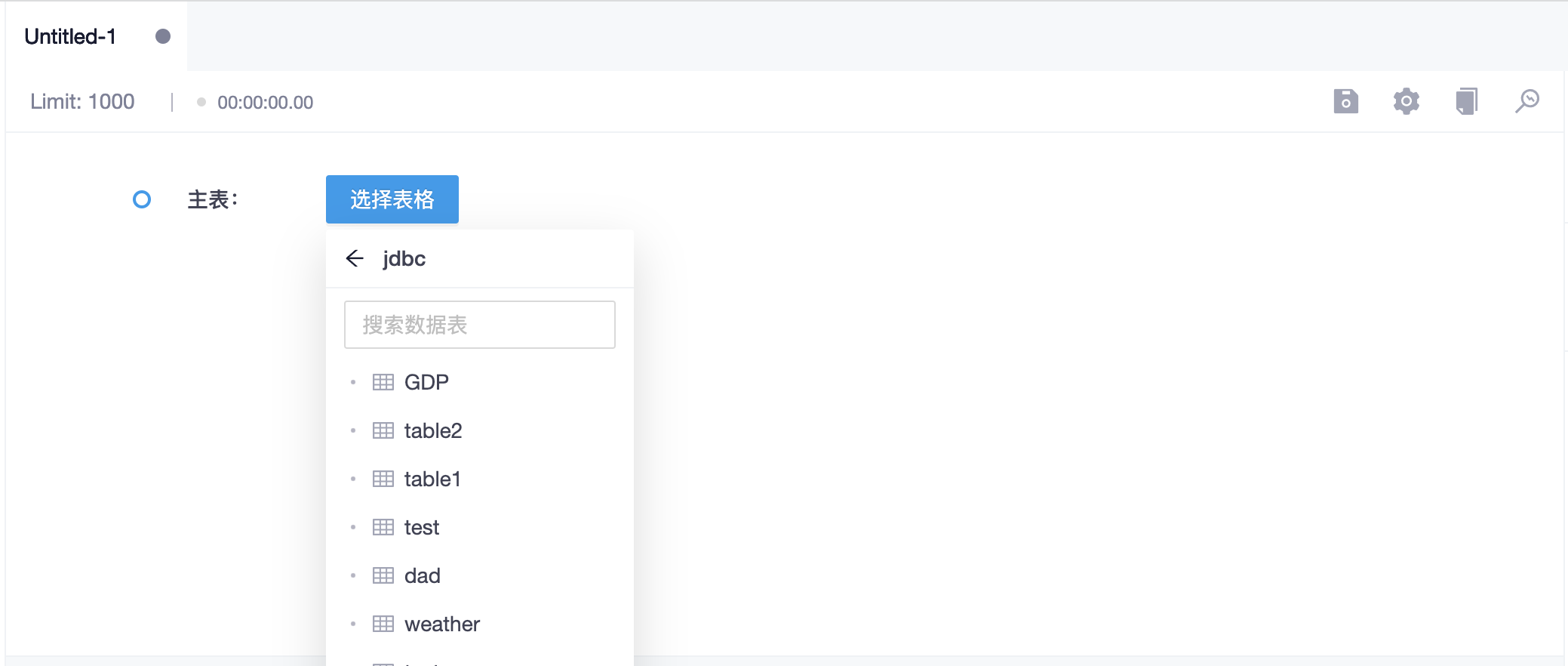
选择完成之后,可以点击主表名称右侧的按钮选择需要展示的字段。如果不需要关联其他表,此时就可以点击下方的“执行”按钮预览结果了
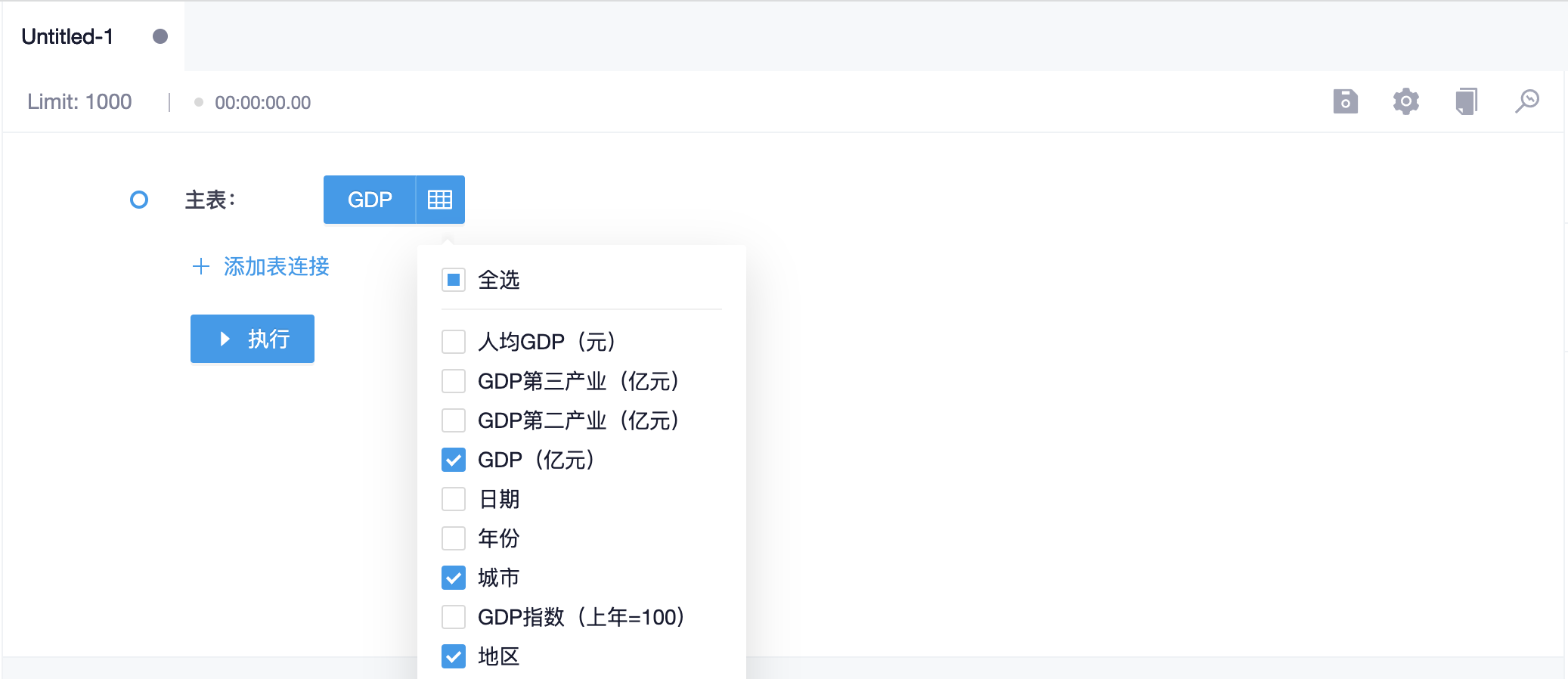
如果需要关联其他表,请点击“添加表连接”按钮,界面上会展示新的配置步骤,在新的配置步骤里配置连接方式和关联表
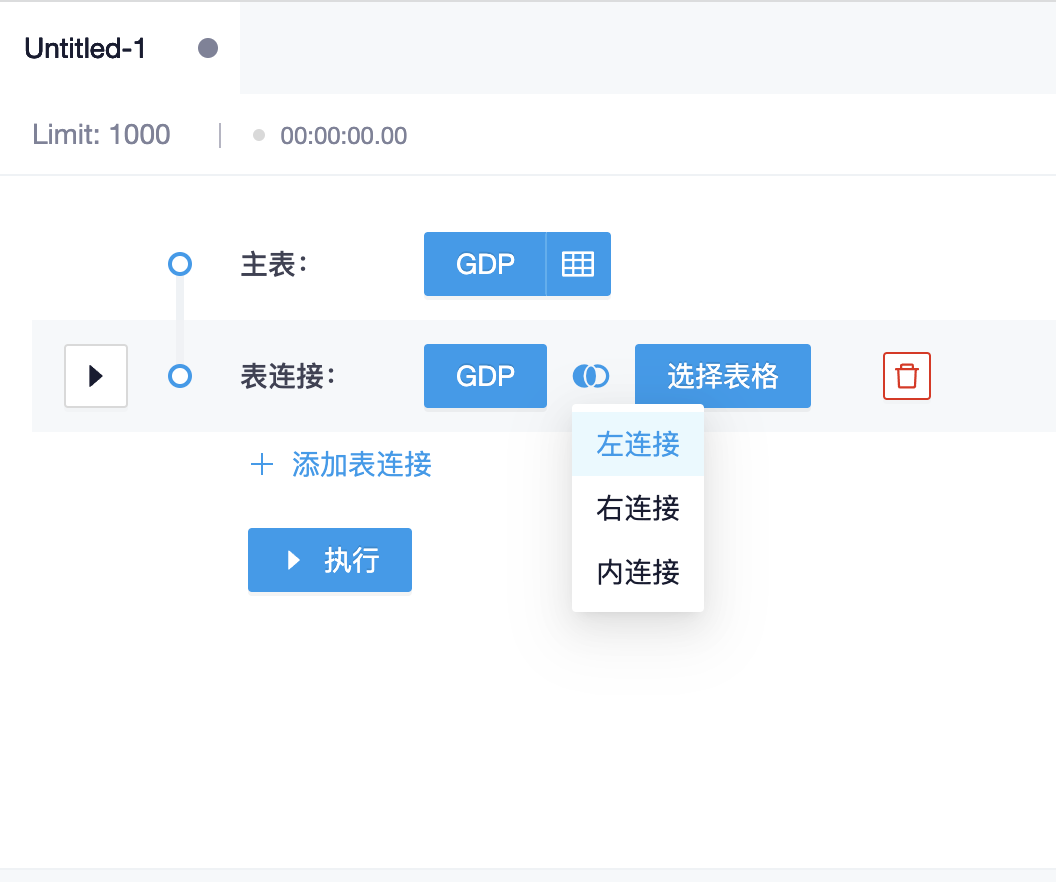
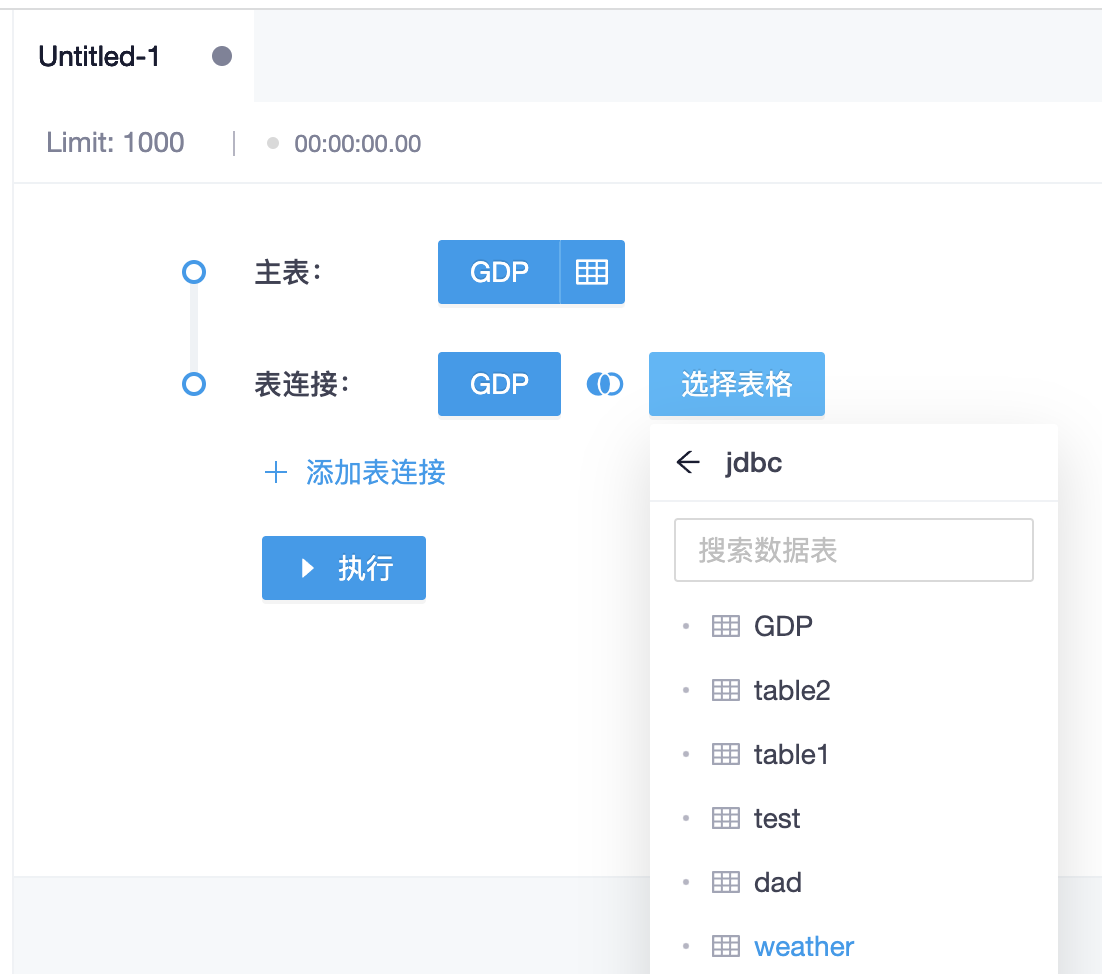
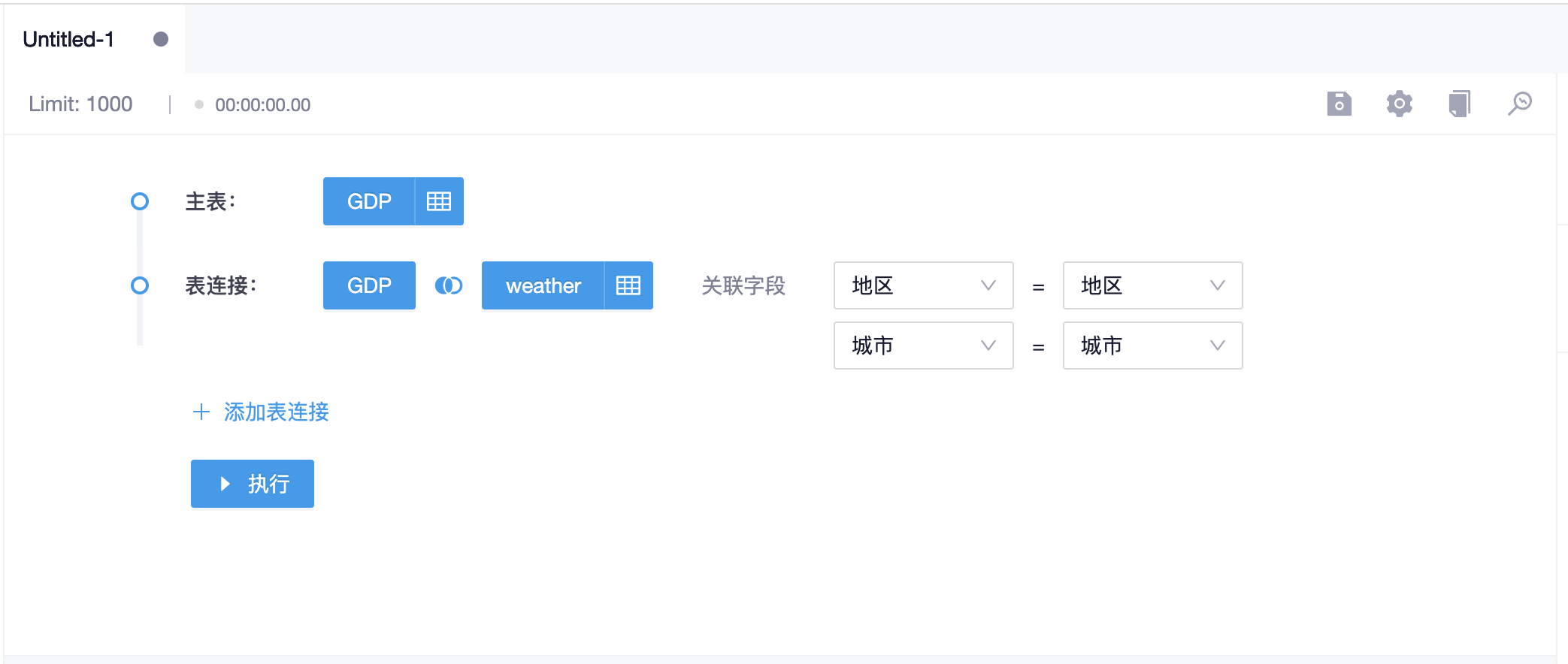
关联表只能从主表的数据源里选择,选择完成之后,同样可以点击关联表名称右侧的按钮选择需要展示的字段。接下来,开始配置主表与关联表之间的字段关系,可以配置多条关系
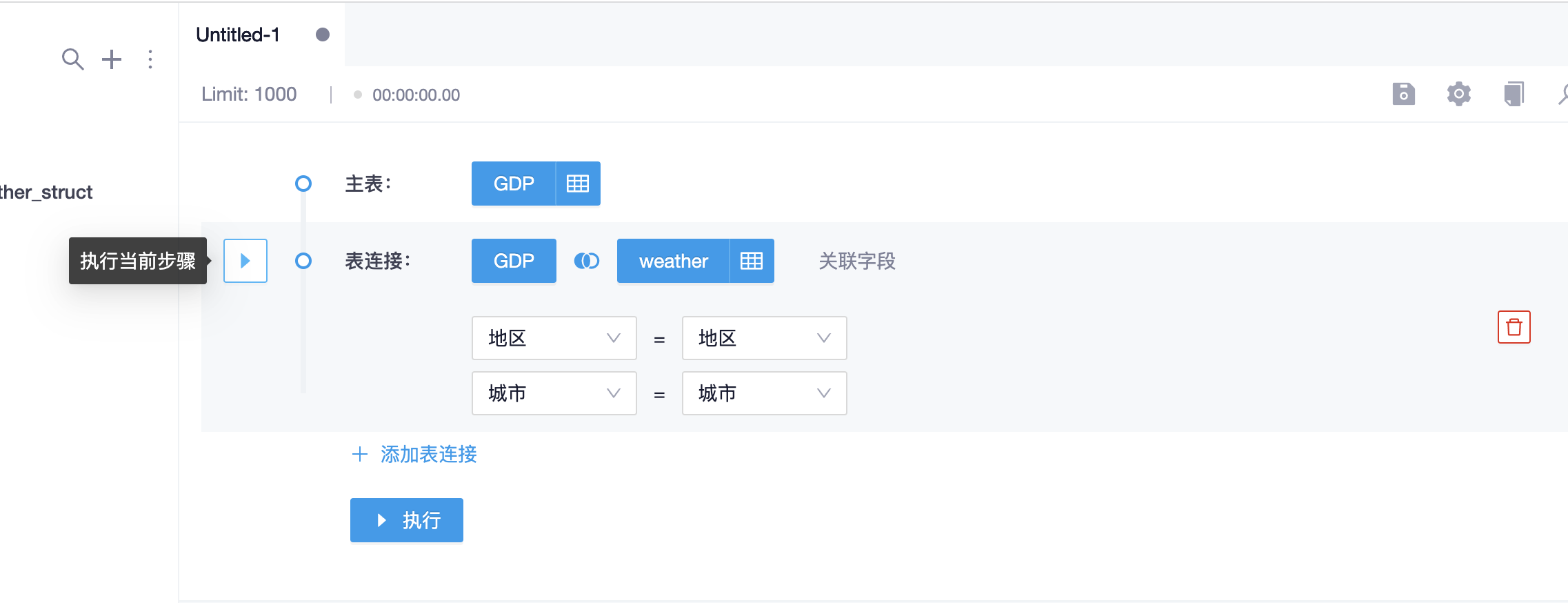
如果需要查看某个步骤的配置结果是否符合预期,可以点击左侧的“执行当前步骤”按钮,在下方面板预览当前步骤的执行结果
配置完成后,如果无需关联其他表,则可以点击下方的“执行”按钮预览结果了;如果还需关联其他表,则继续点击“添加表连接”按钮,重复上述步骤,直到建立完所有表关系
4. SQL 视图
当选择 SQL 视图类型时,编辑区会将会变为代码编辑器,目前仅支持编辑 SQL 语言
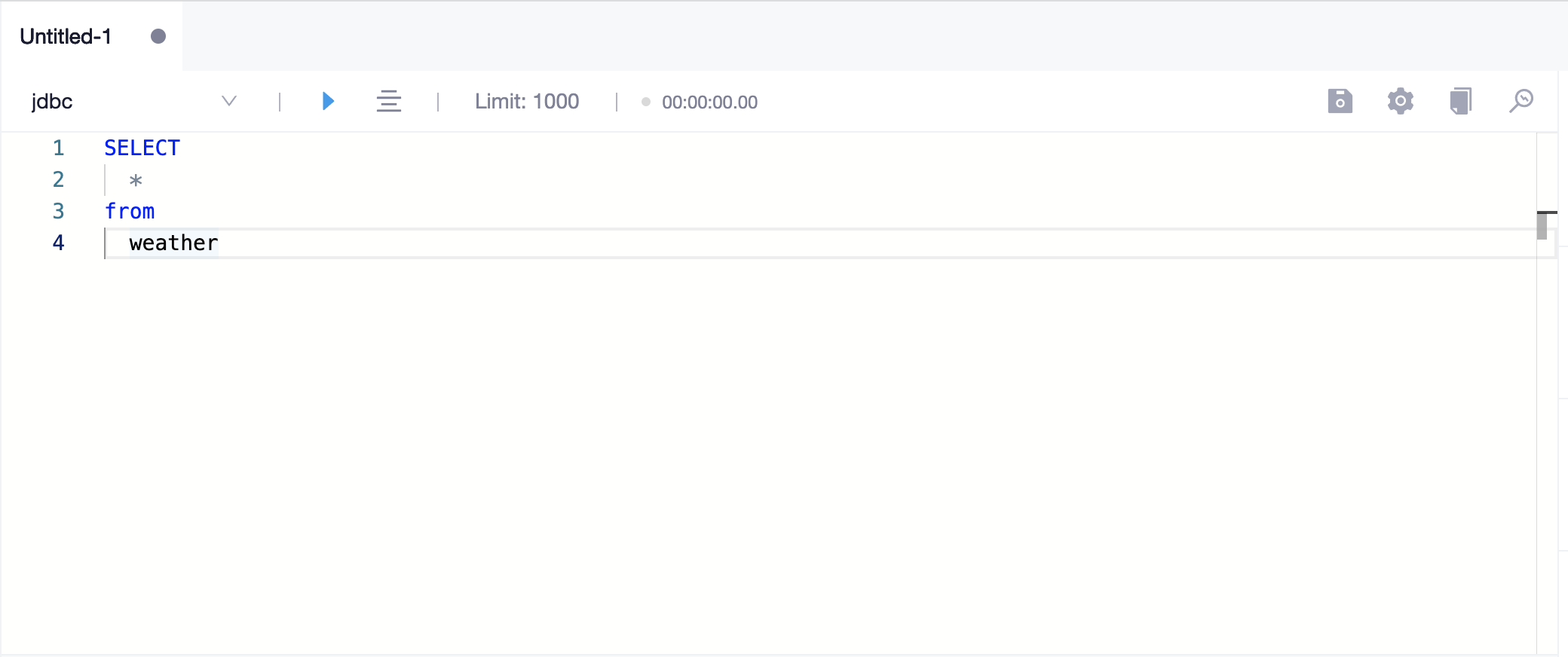
编辑器拥有以下功能:
- 支持常用 SQL 关键字、数据源库/表/字段、变量名称提示
- 支持执行选中 SQL 片段
- 支持快捷键操作
- 执行:
Ctrl / Cmd + Enter - 保存:
Ctrl / Cmd + s
- 执行:
- 工具栏
- 选择数据源
- 执行
- 美化 SQL
- 设置查询结果总行数
- 查询时长记录
- 保存
- 编辑基本信息
- 另存为
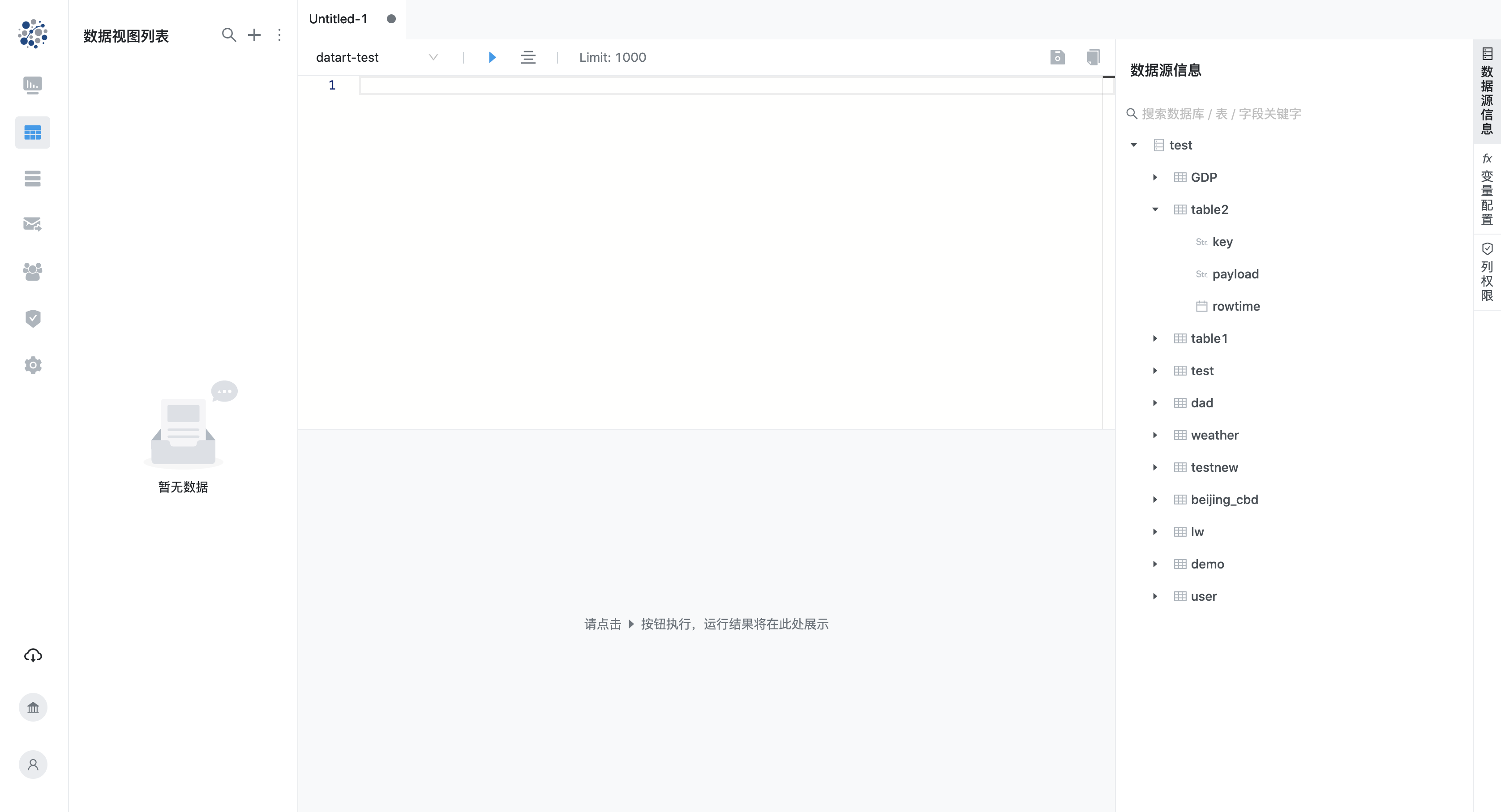
4.1 数据源信息
在编辑器工具栏中选择了数据源之后,打开侧边栏的数据源信息标签页,就可以浏览数据源信息。数据源信息分为数据库、表、字段 3 个层级,通过树状菜单展示,方便编写 SQL 时参考。初始化时默认仅加载数据库信息,点击数据库名称前的扩展图标将会加载该数据库的表信息;同样,点击表名称前的扩展图标将会加载该表的字段信息。树状菜单中已经展示的所有信息在编写 SQL 时会获得提示
4.2 变量设置
在侧边栏变量标签页中可以创建和编辑该数据视图的专有变量,也可以浏览组织下的公共变量, 关于变量功能的详细介绍请参考变量章节。同样,所有变量在编写 SQL 时输入名称前缀时会获得提示
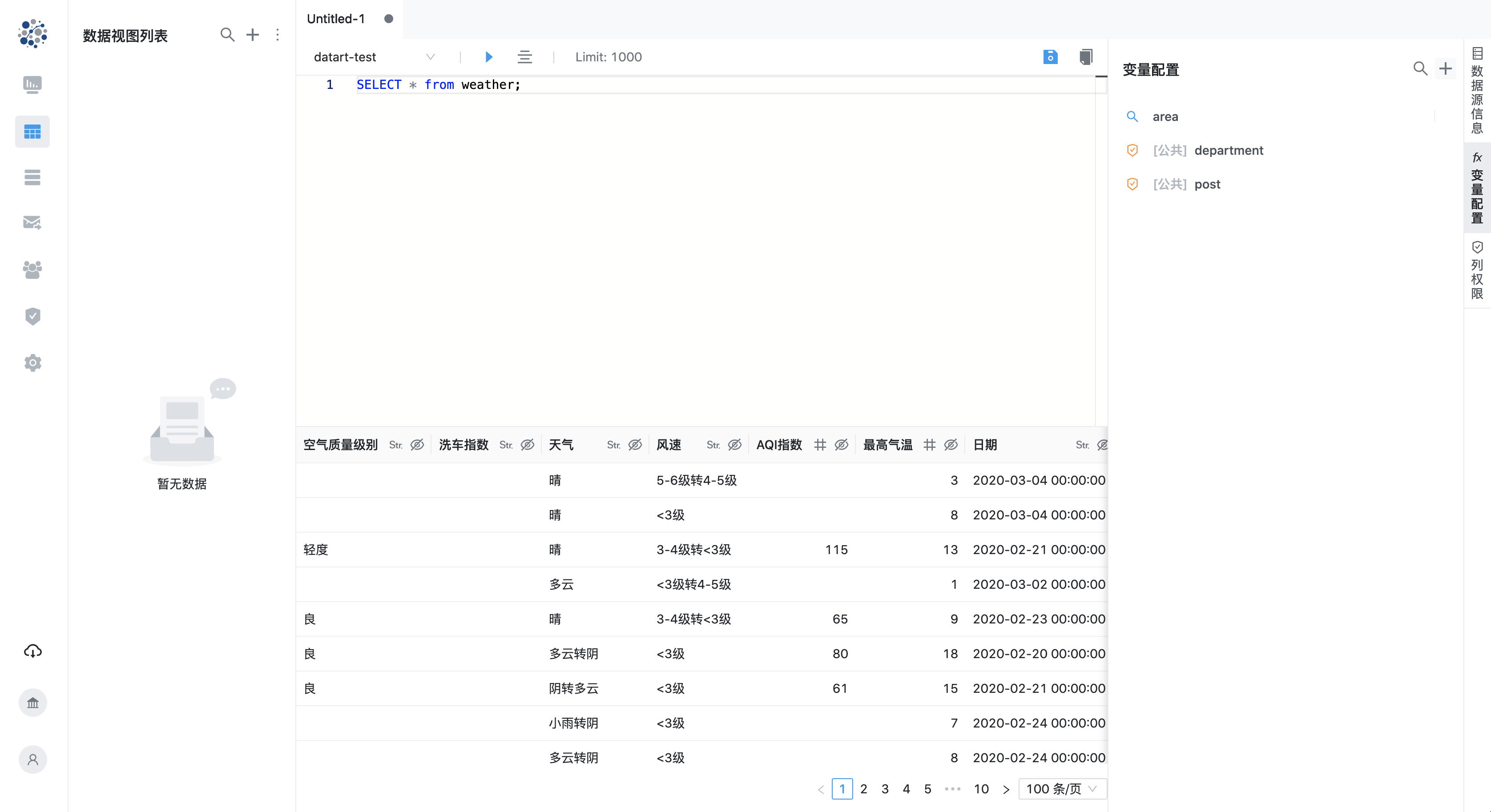
5. 查询结果预览
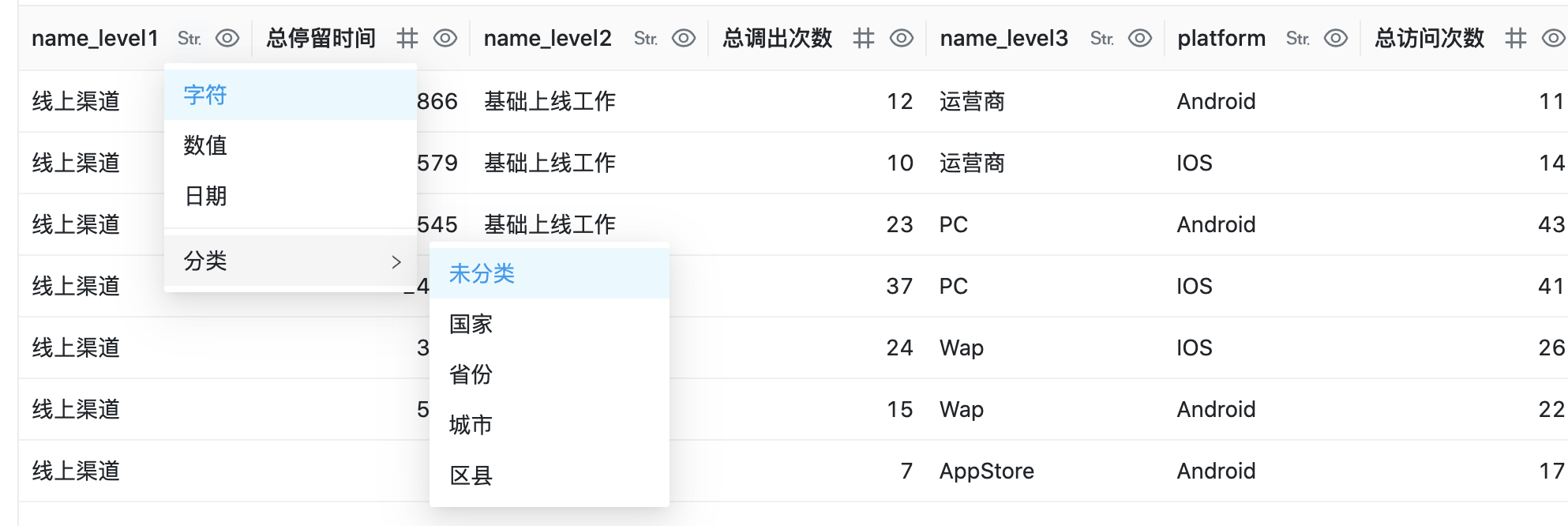
执行成功之后,编辑器下方区域会以表格形式展示查询结果供开发者预览。在表格每列头部,字段名称右侧有两个按钮,分别为字段类型与分类和列权限快捷设置
字段类型共有 字符、数值、日期 3 类,datart 服务端会根据查询结果集的 SQL 类型对字段做默认设置,用户也可以手动进行调整,字段类型将用于数据图表编辑中的数据配置
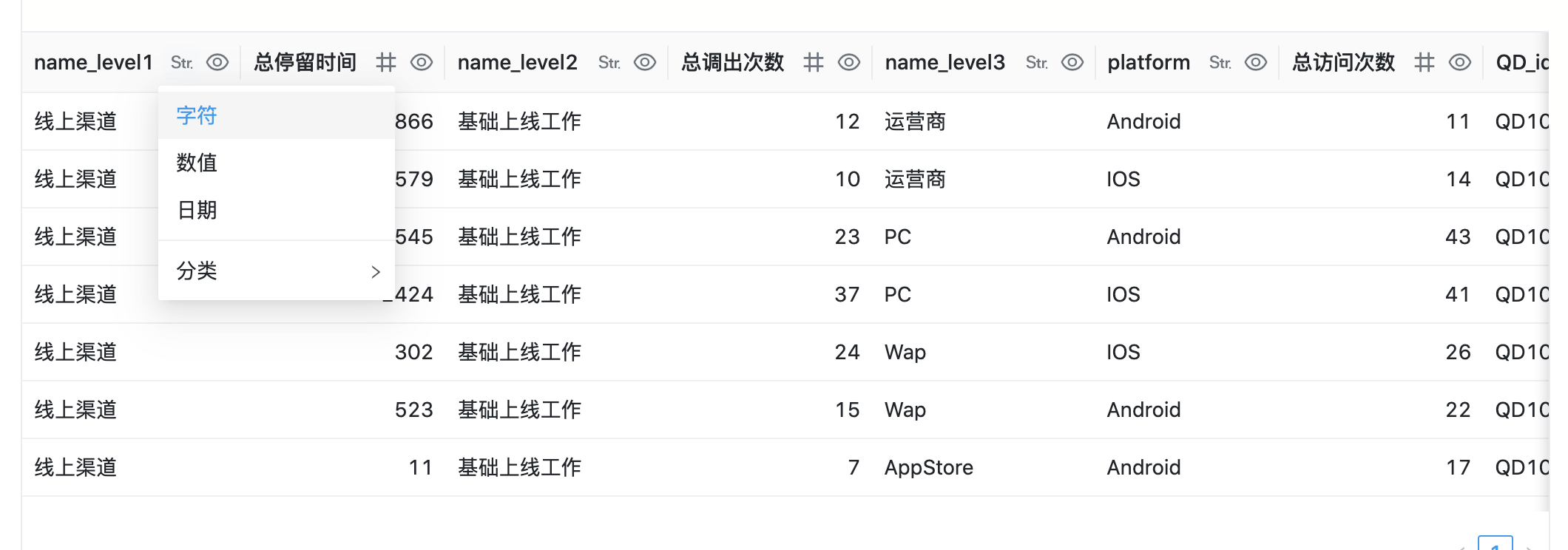
字段分类目前仅用于字段的地理信息属性标记,用于地图层次定位 _(开发中)_,默认值为未分类
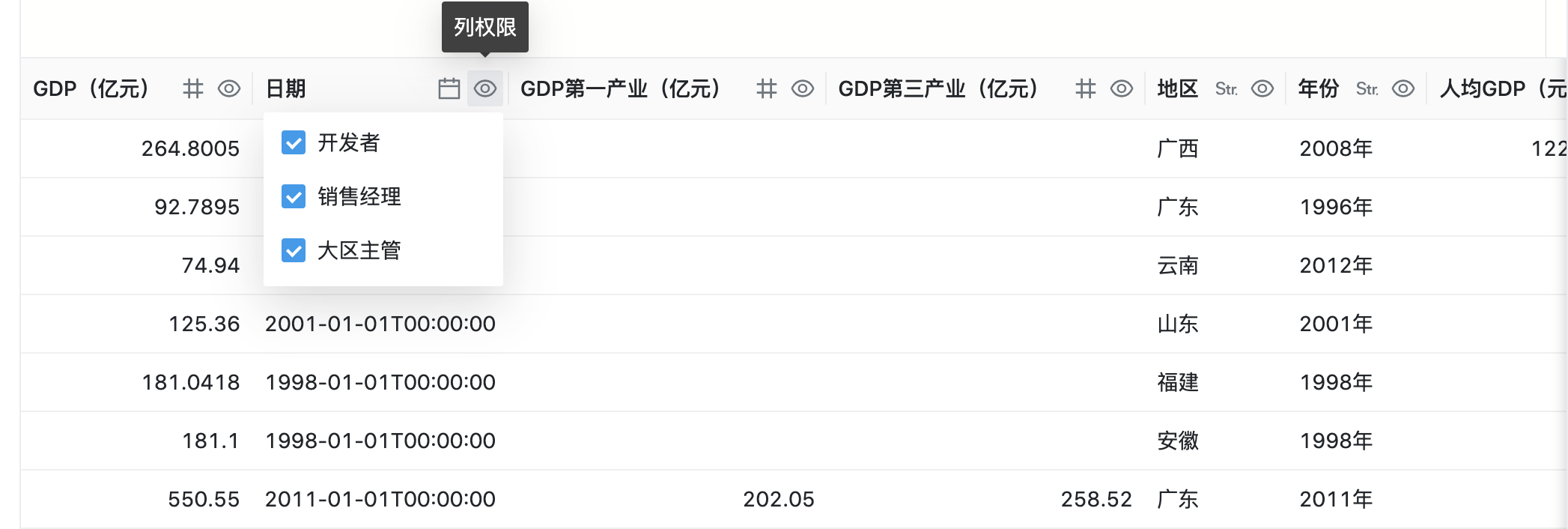
查询结果集中的列权限设置是一个快捷设置,可以快速对字段设置角色的访问权限
6. 数据模型
数据模型记录了当前数据视图查询结果的表结构和字段信息,用于分析时拖拽和配置。用户还可以根据可视化展现的需要,自行修改数据模型中字段的类型或结构。
数据模型面板在侧边栏上,成功执行表关系配置或 SQL 语句之后,会根据查询结果生成默认的数据模型。表视图的数据模型会按照表结构来展示,SQL 视图的数据模型按列表展示
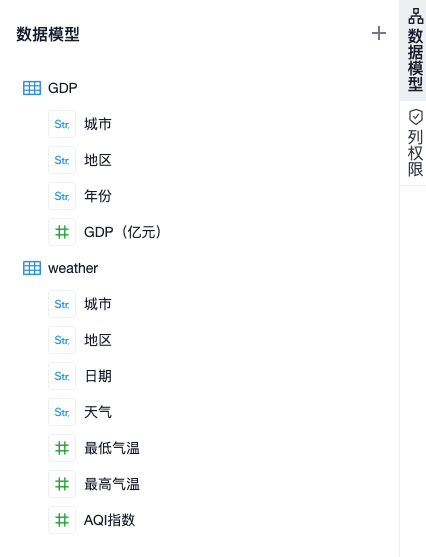
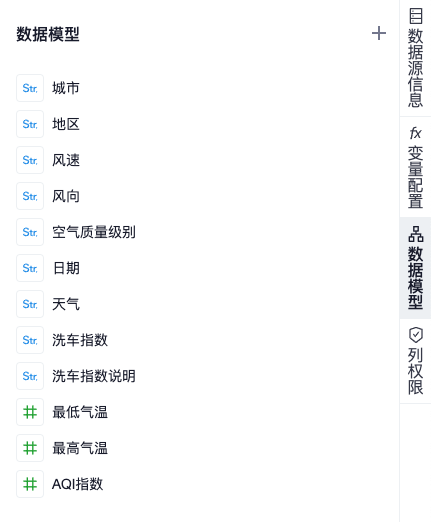
与查询结果预览界面一样,可以点击字段头部的图标,来调整字段类型和分类
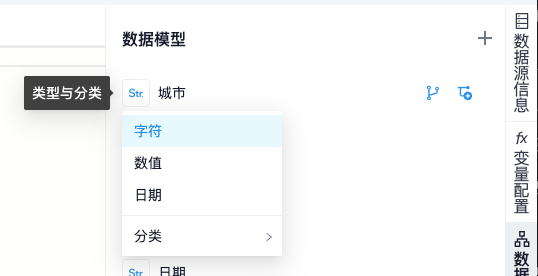
6.1 层次结构
当字段之间拥有层次关系时,可以在数据模型中设置层次结构,帮助分析者更快速地了解字段关系,同时也可以为钻取等功能提供设置便利。
(常见的层次关系如“国家 - 省份 - 城市”,“公司 - 部门 - 团队”)
鼠标悬停在字段上时,右侧会显示两个按钮,分别为“新建层次结构”和“添加到层次结构”
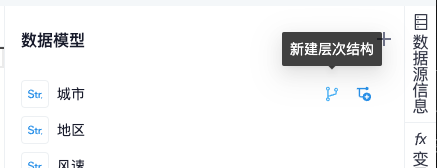
点击“新建层次结构”,在弹窗中输入层次结构名称,点击确定,即可创建一个含有单个字段的层次结构
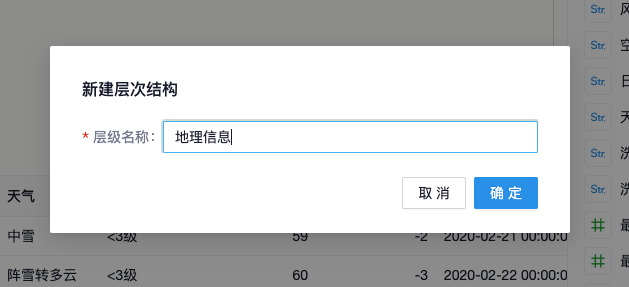

继续往层次结构中添加字段,可以在需要添加的字段右侧点击“添加到层次结构”按钮、选择对应的层次结构名称,也可以直接拖拽字段到层次结构中。还可以在层次结构中拖拽字段来调整顺序
注意,层次结构中的字段顺序是非常重要的

从层次结构中移除字段,点击字段右侧的删除按钮即可;同样,也可以点击层次结构名称右侧的删除按钮来删除该层次结构
层次结构在分析界面中的设置请参考数据图表-钻取设置章节
6.2 计算字段
可以在数据模型中预设计算字段,来达到分析时无需重复创建的目的。数据模型中仅保存计算字段配置,在数据视图中无法预览计算字段的查询结果。
点击数据模型面板右上角的新建按钮来新建计算字段,操作详情请参考数据图表-计算字段章节
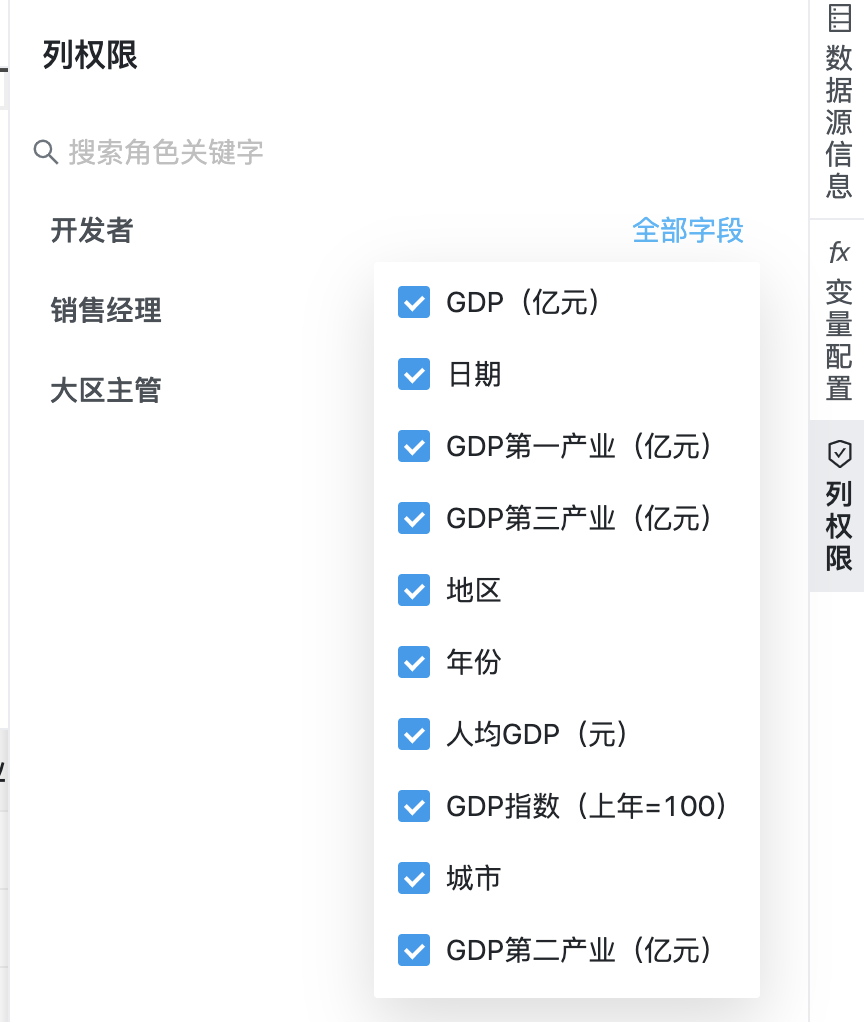
7. 列权限
侧边栏列权限页签中可以设置所有角色的列权限,在这个面板中是以角色为主体来设置对应的列权限

点击列表右侧的按钮,即可在下拉菜单中勾选字段访问权限
8. 高级配置
保存数据视图时,表单上有一组包含默认值的高级配置选项,下面介绍高级配置的用处
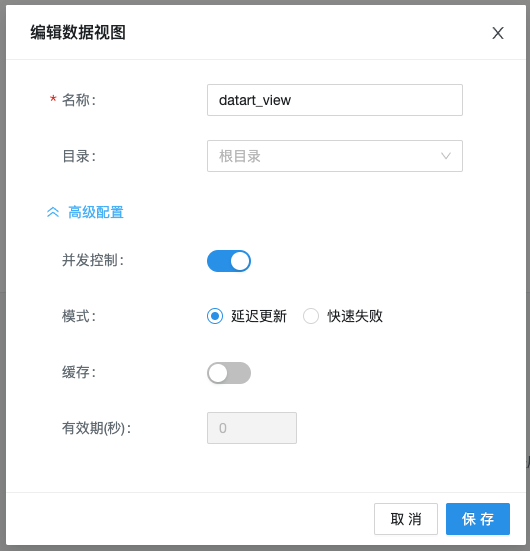
8.1 并发控制
并发控制是使用 datart 服务器对数据视图并发查询进行性能优化;在 SQL 加工逻辑比较复杂、或是数据库负载较大的情况下,反复刷新图表和仪表板会导致数据库积压许多相同的执行任务,并发控制是针对这种场景做的优化,来达到减少数据库的压力、优化使用体验的目的。并发控制仅在可视化中生效,在数据视图开发阶段无效。datart 目前支持两种并发控制策略:
延迟刷新
使用延迟刷新时,来源于同一个数据视图、SQL 语句完全相同的请求,在首次查询没有执行完成的情况下,后续的查询不会真正发送到数据库,而是在服务器队列中处于等待状态;直到首次查询返回结果,服务器会将本次查询结果返回给所有队列中的查询,然后清空队列,进入下一个周期
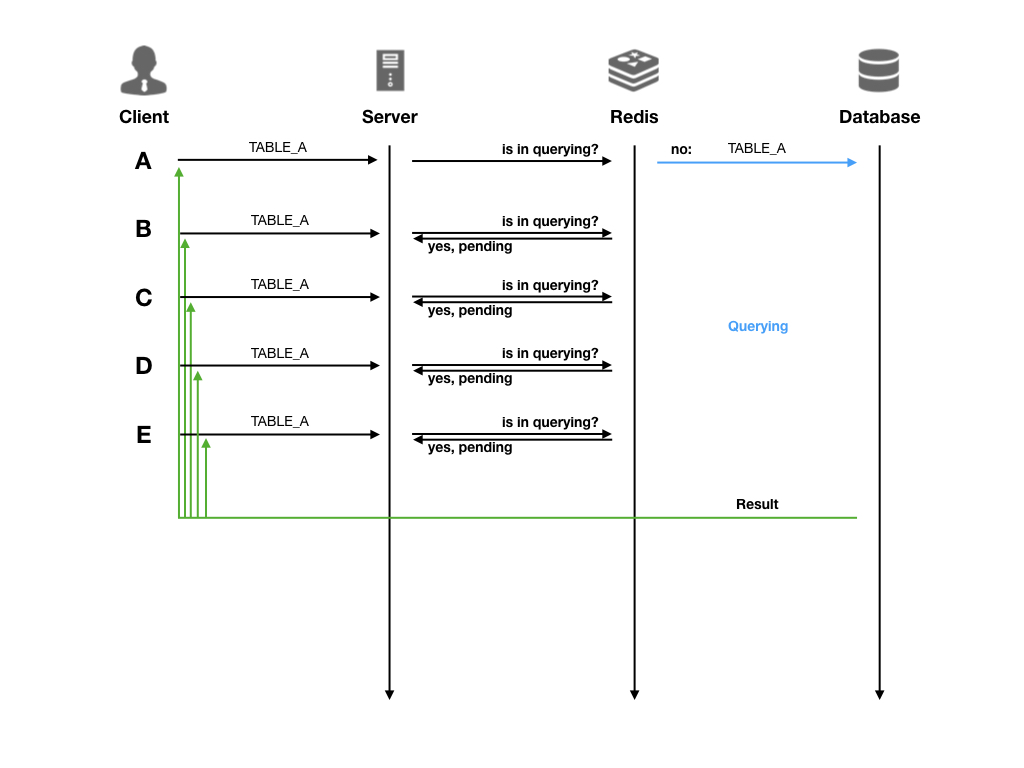
例如某个数据视图查询需要 10 分钟,那么第一条查询发起后的 10 分钟内,相同 SQL 语句的查询将不再发送到数据库执行;直到第一条查询结果返回之后,这 10 分钟内发起的所有相同 SQL 语句的查询将会拿到同样的结果
因此,延迟刷新的副作用是会导致数据时效性受到影响,就拿上面例子来说,第 9 分钟时发起的查询,虽然只等待 1 分钟就得到了结果,但从时效性来说,它拿到的是 10 分钟之前的查询结果。因此,对时效性要求较高的场景,开发者可以手动关闭并发控制选项
延迟刷新在创建数据视图时被默认开启
快速失败 (开发中)
与并发控制处理方式不同,在使用快速失败时,来源于同一个数据视图、SQL 语句完全相同的请求,在首次查询没有执行完成的情况下,后续的查询会直接响应带
400状态码的错误信息,告诉使用者该执行任务处于占用状态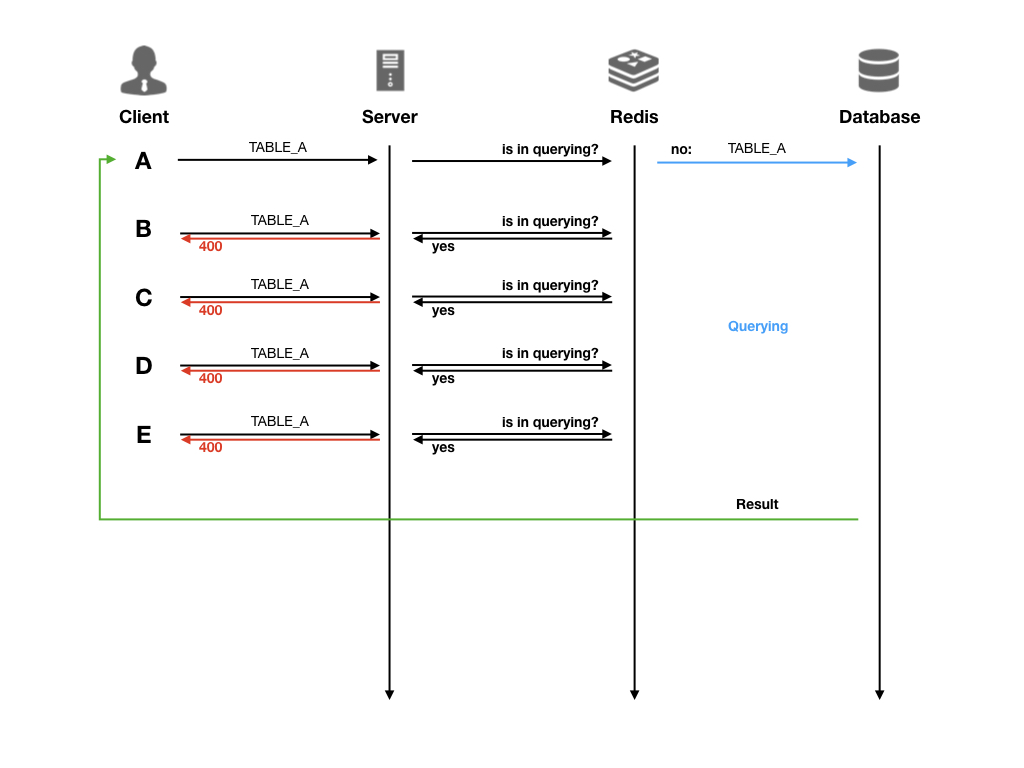
并发控制功能依赖 Redis,使用并发控制功能需要确保 Redis 已正确配置
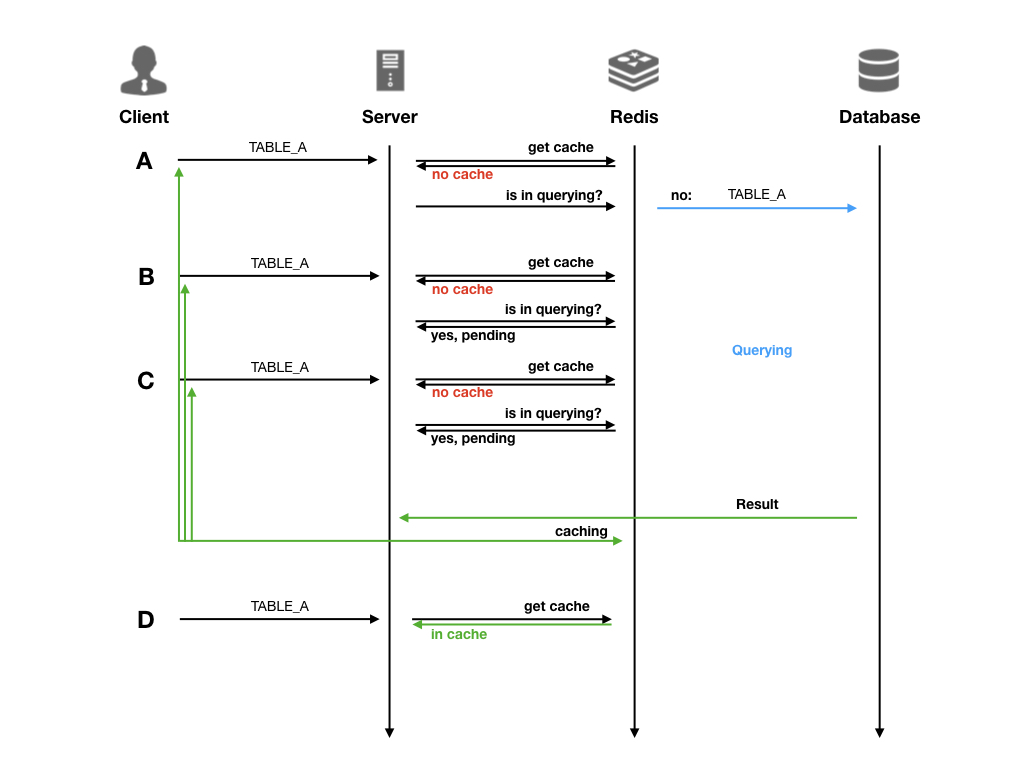
8.2 缓存
datart 支持缓存查询结果数据,开启之后,在可视化中查询数据时,首次查询结果会被缓存起来,使用 SQL 语句作为索引;在之后缓存有效期内的所有相同 SQL 语句的查询均会直接返回缓存结果
缓存功能同样依赖 Redis,使用缓存功能需要确保 Redis 已正确配置
缓存与并发控制是独立作用的,可以一起开启,在一起开启的情况下工作机制如下图:
9. 基础功能
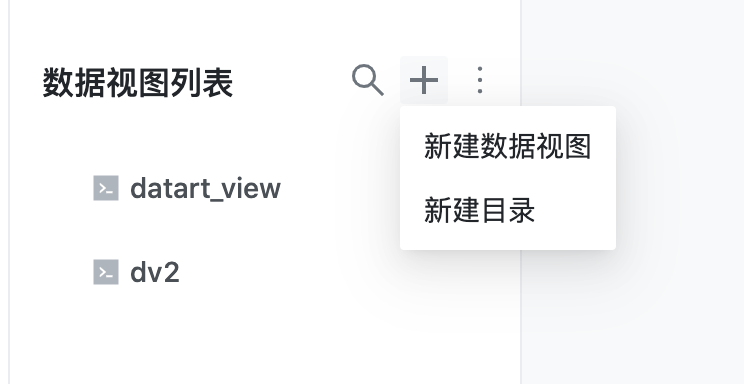
9.1 新建数据视图和目录
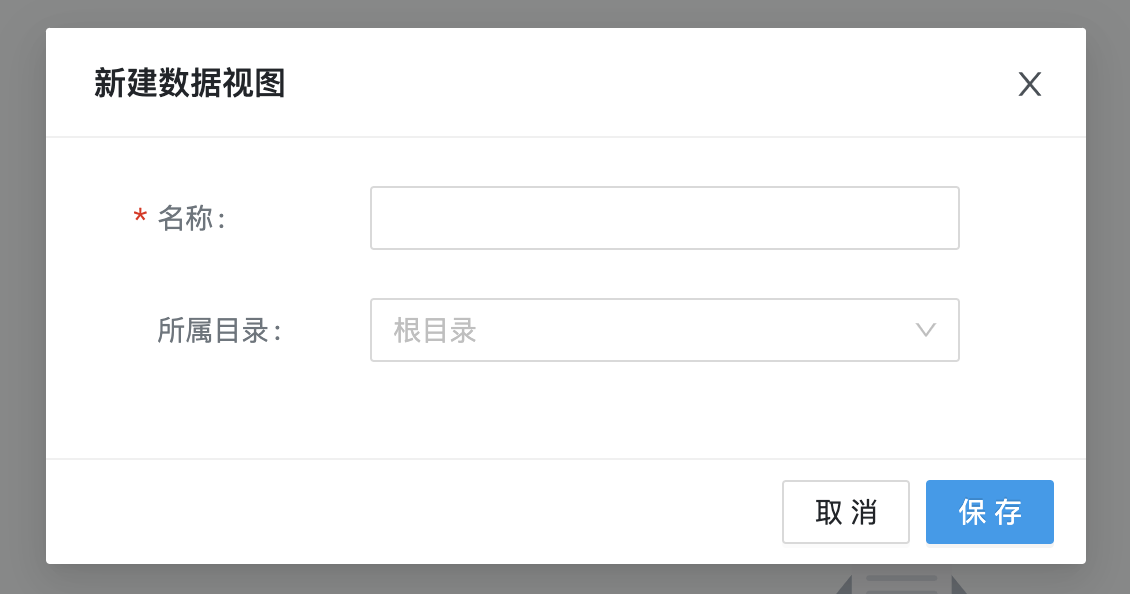
点击数据视图列表顶部的加号按钮,选择新建数据视图时会在右侧新增页签,编辑完成后才能保存;选择新建目录会弹出新建目录表单,填写名称和所属目录即可完成创建
9.2 编辑基本信息
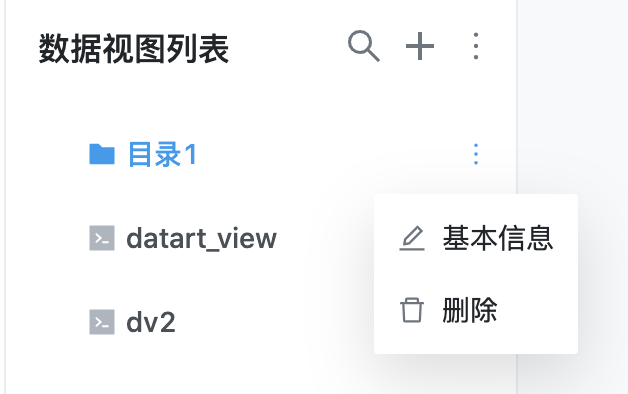
点击数据视图列表右侧的扩展按钮按钮,选择基本信息,即可对数据视图/目录的基本信息进行编辑
9.3 删除目录/移至回收站
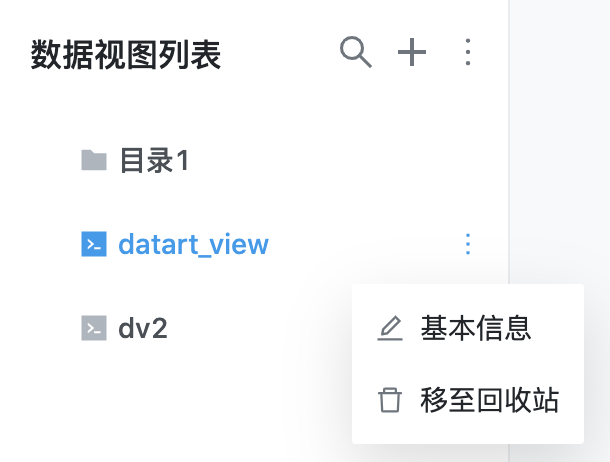
点击数据视图列表右侧的扩展按钮按钮,如果是目录,会显示删除按钮,点击并确认之后会永久删除该目录;如果是数据视图,会显示移至回收站按钮,点击并确认之后,该数据视图会被移动到回收站归档,无法再被使用
9.4 还原
点击数据视图列表顶部的扩展按钮,进入回收站
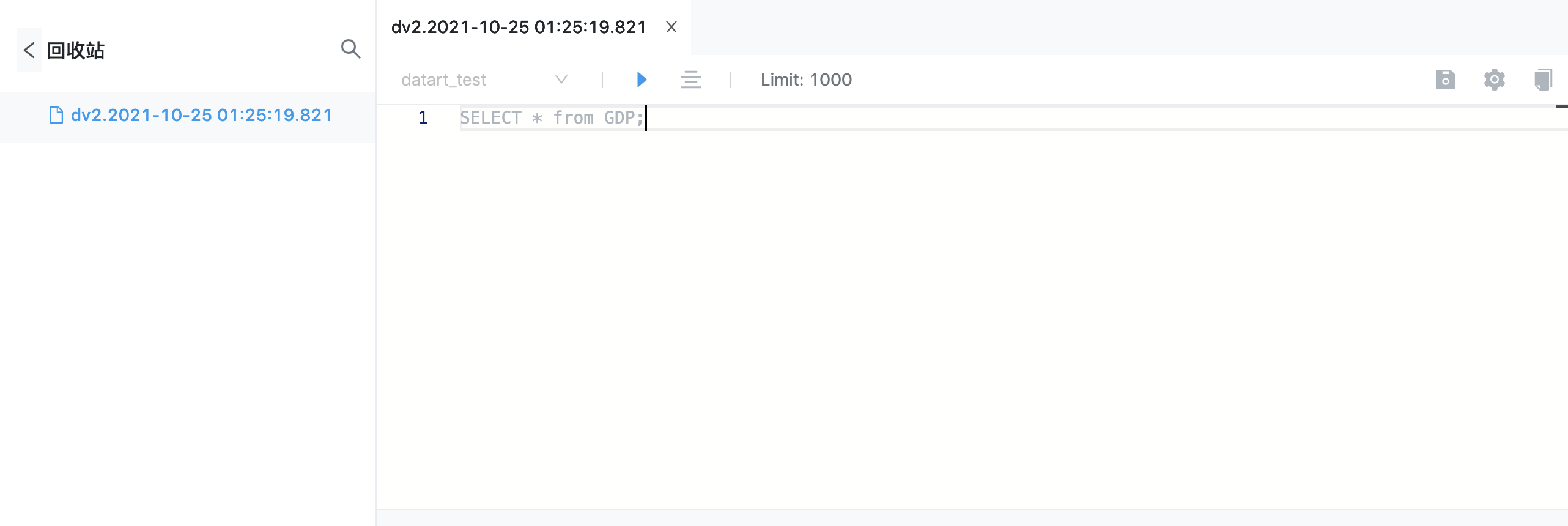
系统会将移至回收站的数据视图重命名,规则为原名称.时间戳;点击回收站列表的任意数据视图,右侧区域会展示该数据视图的详细信息,为只读状态
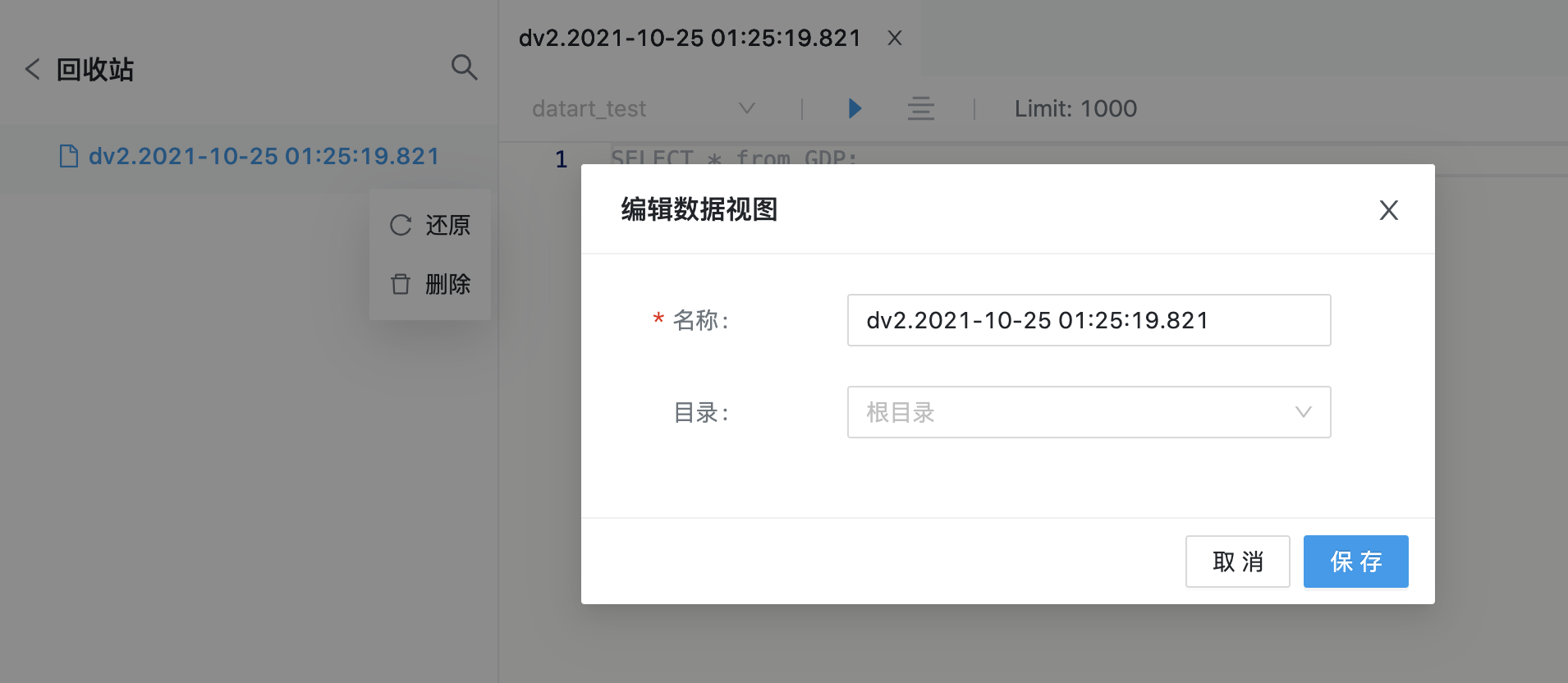
点击列表右侧扩展按钮,选择还原,在弹窗表单中需要重新填写还原后的名称和目录,填写完成后,点击保存按钮完成还原
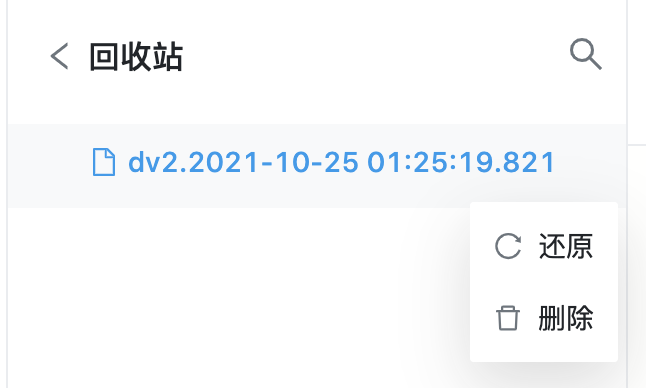
9.5 删除
查看回收站列表里的数据视图信息时,点击列表右侧扩展按钮,选择删除,确认对话框之后,将会永久删除该数据视图
9.6 搜索
点击数据视图列表顶部的搜索按钮,会弹出关键字搜索框,可以按照名称检索数据视图